What if an onboarding paid attention to you?
-
The problem: Glassdoor was building an LLM-driven onboarding for its AI career assistant. The flow worked but no one had worked out how the assistant should sound, or how to keep that consistent across nine phases of conversation.
The solution: Authored the conversation design and prompt work across every phase of guided onboarding. Restructured the phase order, grounded acknowledgments in what the user shared, and built shared persona rules every phase inherits. So the assistant didn't just complete onboarding, it felt like it was listening the whole way through.
What does it feel like to be onboarded by something that's actually paying attention?
Something more like a conversation a friend would have with you. That was the bar I wanted to hit.
The LLM onboarding at Glassdoor is nine phases of conversation between the assistant and a new user. The content design and prompt work are my responsibility. This is a look at a slice of that ongoing work: aka improving how the whole system listens.
Okay, so the onboarding was, by technical measures, working (most of the time). LLM nondeterministic tendencies and all. Users completed it. They reached the first job match.
But anyone who actually used it could feel the thing was running on rails.
Early users had been telling us the chat felt transactional, more form than conversation. The diagnosis was half-right. The intro needed work.
But the failure mode wasn't "the user doesn't know what Door is." It was: the assistant doesn't feel like it's listening overall.
I had a choice. Do the original request. Clean content design job. Fix the copy. Update the prompt.
Or push back and argue for something bigger. Fix the moment.
So I did.

PM agreed. Which mattered more than the rewrites, honestly.
Before we go any further, a quick overview might be valuable.
Onboarding is a state machine. Each phase is a YAML block with its own prompt, its own tool list, and its own required fields. The user moves through them in rank order. Each phase knows what it owns and what to ask for next.
Each phase runs two streams.
The primary stream reads the user's message, decides which tool to call (save_profile, confirm_resume_step, generate_resume_card...), saves what the user just shared, and writes a brief acknowledgement. The acknowledgment is grounded in what was just captured. It does not ask the next question.
The follow-up stream runs immediately after. It doesn't call tools. Its only job is to ask the next phase's question and to feel like a continuation of the acknowledgement, not a hard cut.
Both streams inherit from a shared persona block at the top of the YAML file (universal tone rules, response shapes, anti-patterns, etc). Every phase references it. Nothing repeats. When something needs to apply everywhere, it lives in persona.
So when I say "I rewrote the followUpPrompt blocks for both phases," those are the prompt strings the follow-up stream reads. When I talk about an "ack" or "response," that's what the primary stream emits.
I didn’t define this architecture, BE did. I just inherited it. That's the box the work lives in.
First move was to well… move desired job title (CAREER_GOAL) up and Current job title (EMPLOYER) down.
Why do that you say? Also, on behalf of my engineers also questioning it.
Well… I argued the ordering was part of the problem.
Aspiration before logistics changes the emotional framing. When you ask “what are you reaching for?” before “where do you currently work?” it reframes onboarding as a partnership instead of an intake form.
Makes it more hero’s journey, less checklist.
BEFORE: EMPLOYER → CAREER_GOAL → LOCATION → ... (logistics first) AFTER: CAREER_GOAL → EMPLOYER → LOCATION → ... (aspiration first)
Next, was updating the desired job title framing altogether. It’s new home changed it’s meaning. For the better.
Most onboarding systems accidentally reduce career movement into a binary. Stay or leave. But real career shifts usually fall into three buckets. Stay where you are, step up, or pivot sideways into something new.
┌──────────────────────────────────────┬──────────────────────────────────────┐ │ BEFORE │ AFTER │ ├──────────────────────────────────────┼──────────────────────────────────────┤ │ │ │ │ ╭────────────────────────────╮ │ ╭────────────────────────────╮ │ │ │ "Do you want to keep │ │ │ "You're a Senior PM. │ │ │ │ going as a [title], step │ │ │ What's pulling you next? │ │ │ │ up into something more │ │ │ More of this, something │ │ │ │ senior, or shift into a │ │ │ bigger?" │ │ │ ╰────────────────────────────╯ │ ╰────────────────────────────╯ │ │ 22 words. One sentence. Mouthful. │ 16 words. Three sentences. │ │ │ Conversation. │ │ │ │ ├──────────────────────────────────────┼──────────────────────────────────────┤ │ │ │ │ followUpPrompt: | │ followUpPrompt: | │ │ Ask about their career direction │ Ask about their career direction: │ │ — what kind of role they're │ the role they want next. │ │ targeting next. Be curious. If │ One question, 1-2 sentences. │ │ the collected profile has a │ │ │ currentJobTitle, reference it │ If currentJobTitle is in │ │ to frame the question and │ collected, lead with the title, │ │ surface all three directions │ then the three directions: stay │ │ the user could go: staying at │ at the same level, step up into │ │ the same level, stepping up │ something more senior, or pivot │ │ into something more senior, or │ into a different kind of role. │ │ pivoting into a different kind │ Do NOT frame it as binary "stay │ │ of role. Do NOT frame the │ vs change" because that hides │ │ question as only "stay vs │ the level-up option. Examples: │ │ change" — that hides the │ - "You're a [title]. What's │ │ level-up option. E.g., "Do you │ pulling you next? More of │ │ want to keep going as a │ this, something bigger?" │ │ more senior, or shift into a │ - "[Title] at [employer]. Where │ │ different kind of role?" Adapt │ are you trying to land? │ │ the phrasing naturally. │ Deeper in, up a level, or │ │ One question, 1-2 sentences. │ somewhere new?" │ │ │ │ │ │ If currentJobTitle is NOT in │ │ │ collected, ask openly. Do NOT │ │ │ mention "more of the same" or │ │ │ any stay-vs-change framing. │ │ │ Examples: │ │ │ - "Tell me what you do. Where │ │ │ are you trying to take it?" │ │ │ - "What role are you building │ │ │ toward?" │ │ │ │ └──────────────────────────────────────┴──────────────────────────────────────┘
But staging caught something evals couldn't. Double-personalization. The primary stream's acknowledgement landed cleanly:
"Senior PM at Meta tells me you can run at serious platform scale. Director feels like a clean next chapter."
But the follow-up stream would then open with:
"Senior PM at Meta is a strong foundation. So where are you based right now?"
Same role and employer, said twice in a row.

Luckily it was a single edit to FOLLOW_UP_TONE in the follow-up stream's prompt:
// OnboardingFollowUpStreamService.kt const val FOLLOW_UP_TONE = """ ... - Reference the user's just-saved input naturally. + NEVER restate, summarize, or echo back information that was + just confirmed. The user already saw the acknowledgement. + Open with a short transition phrase that bridges from the + ack WITHOUT echoing the saved field. Examples: "Since...", + "Given that...", "Now...", "So...". ... """
Once the structure was right, the content of the acknowledgment was still flat.
I identified three phases EMPLOYER, CAREER_GOAL, and COMPENSATION and gave two of them grounded beats that reflect something meaningful back instead of echoing the field.
The interesting design question lived in CAREER_GOAL.
The reasonable instinct would be give users a brief market signal for the desired title. Giving the user context about the role they want. Sounds good.
But there's no fetch_role_demand tool. And I won’t be getting one anytime soon.
So I reframed the question. Given we have the user's current role and the role they want next.
What's the most meaningful beat we can add to this moment?

Direction-naming. Stay, step up, pivot. The model has both data points. It can honestly name the move the user is making. The acknowledgment is for the user, not the system.
They just told us where they want to go. The warmest thing we can do is reflect that move back to them as a story they recognize as their own. That helps build connection.
A clean step-up earns real recognition. A stretch step-up earns honest language, not false reassurance. That honesty build trust.
That's the context the market signal was trying to give them, grounded now in what they actually said, not in what the model would have invented.
But all this did not come without learnings…
The first surfaced in eval CI. The RESUME_UPLOAD acknowledgement kept merging with the next phase's question:
"Got it, resume confirmed. Let's dive into your job preferences. What job title are you aiming for?"
The prompt already said "DO NOT ASK THE NEXT ONBOARDING QUESTION." The rule was there.
Why you no listen robot…

Turn out a negative instruction with no examples has no teeth.
So I put the model's own failure trace into the prompt as a Bad example, almost verbatim. The model recognized its own failure shape and stopped reproducing it. Yay.
The second surfaced a few weeks later. I came back to the prompt for a different ticket. Different phase, different problem. But I scanned the EMPLOYER block on the way through, because it was the work I was proudest of.
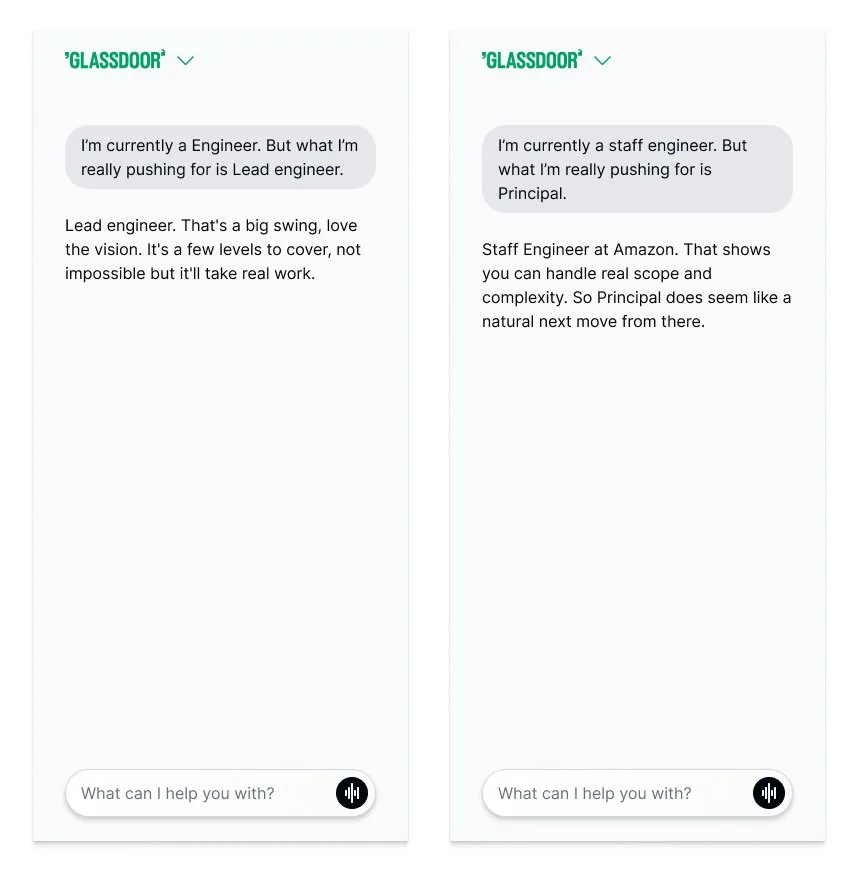
The micro-reward pattern and example I shipped looked like this:
"Staff Engineer at Amazon. That shows you can handle real scope and complexity. So Principal does seem like a natural next move from there."
Three sentences. Confirm-the-field, interpret-the-capability, bridge-to-the-goal.

But on a reread, my content designer brain broke a little bit. The first sentence was dead weight.
"Staff Engineer at Amazon." is a weak confirmation beat. A form receipt before the warmth arrives. I'd written it that way because the structure made sense. Confirm, then interpret, then bridge.
I'd built the rule first and the sentence second. The reader was meant to feel warmth, but it was in sentence two. They were getting a form receipt in sentence one.
So now the version living in the prompt today fuses the naming into the interpretation:
"Senior PM at Meta tells me you can run at serious platform scale. Director feels like a clean next chapter."
Same principles, tighter shape. My original line… now lives in the what not to do part of the prompt 🤣
Good: "Senior PM at Meta tells me you can run at serious platform scale. Director feels like a clean next chapter." Bad: "Staff Engineer at Amazon. That shows you can handle real scope. So Principal does seem like a natural next move." (stubby confirm-beat; should be fused into one sentence)
Iteration log (selected moments)
-
The setup. After Pass 1 reordered the phases and rewrote the followUpPrompt blocks, the new acks felt clipped at one sentence. I relaxed the Response rule to "1–2 sentences" to give the model room to be warm.
What broke. The model read the latitude as license. It started merging the primary ack with the next phase's question. Traces showed outputs like "Got it, Senior PM at Meta. So where are you currently located?" — the primary stream doing the follow-up stream's job. The eval assertion primaryNotContains: [?] failed across CAREER_GOAL and EMPLOYER.
The fix. Tightened the Response rule back to one sentence, end with a period, no questions allowed. Hard boundary, not a range.
What it taught me. An LLM reads optional length as permission to keep going. Don't give it a soft ceiling when you mean a hard one.
-
The setup. A few weeks before this work, an upstream ticket renamed the desired-title field from singular desiredJobTitle to a plural array desiredJobTitles[] to support users targeting multiple roles. The schema change shipped; the prompts and eval files moved with it.
What broke. Or so I thought. My eval assertions still checked the old singular field. When I ran the suite against the new prompts, every save_profile check silently mismatched. The tests had been failing for a reason that had nothing to do with my changes.
The fix. Updated every assertion in the suite to the new field name. No prompt change required — the prompts had been right the whole time.
What it taught me. When evals fail on first run, the answer is rarely just the prompt. Field renames upstream can poison downstream test assertions for weeks if no one trips them. Check the assertions before assuming the prompts are wrong.
-
The setup. After Pass 1 shipped, staging surfaced an unexpected pattern. The primary stream would confirm a saved field warmly — "Got it, Senior PM at Meta — great target." Then the follow-up stream would open with the same details — "Senior PM at Meta is a solid track..." The user heard the same facts twice in a row.
What broke. My first instinct was per-phase patches: add language to each phase's followUpPrompt telling it not to restate. That worked for CAREER_GOAL and EMPLOYER. A few weeks later, when new phases were added to the flow, the same double-personalization appeared in each. The patch hadn't generalized — each new phase needed its own copy of the rule.
The fix. Single edit to FOLLOW_UP_TONE in OnboardingFollowUpStreamService.kt, the Kotlin const every follow-up stream reads. One rule about using short transition phrases ("Since...", "Given that...", "Now...", "So...") without echoing the saved field. Applied everywhere automatically.
What it taught me. When you find yourself patching the same problem in multiple places, the patch is in the wrong place. Look for the shared parent and fix it there once.
-
The setup. The RESUME_UPLOAD prompt already had a clear rule: "CRITICAL: DO NOT ASK THE NEXT ONBOARDING QUESTION in this turn." It was marked critical. It was in caps. It was unambiguous.
What broke. The model ignored it. Traces showed completions like "Got it, resume confirmed. Let's dive into your job preferences. What job title are you aiming for?" — exactly the failure mode the rule was supposed to prevent. The eval guided-onboarding-resume-confirm-freetext was going 0 of 3.
The fix. Added a FORBIDDEN list with three named patterns (bridging phrases, previewing the next step, asking any questions) plus Bad examples lifted verbatim from the failure traces. Each Bad example was paired with a parenthetical reason — "(bridges + asks)", "(previews next step)" — so the model had a diagnosis of why each failure was wrong, not just an example to avoid. Eval went 0/3 to 3/3 on the next run.
What it taught me. Negative rules have no teeth without negative examples. A rule describes what you want. An example, lifted from a real failure trace, shows the model what to recognize and avoid. The fix wasn't a louder rule. It was a different kind of rule.
-
The setup. This work introduced a micro-reward pattern for EMPLOYER acknowlegement — two-to-three short sentences that reflect something meaningful back to the user instead of echoing the field. I designed a three-sentence shape: confirm the field, interpret what it shows, bridge toward the desired goal.
What broke. Nothing. By the metrics. My example shipped as the canonical Good case: "Staff Engineer at Amazon. That shows you can handle real scope and complexity. So Principal does seem like a natural next move from there." It passed every eval. It made me proud. Then weeks later, I came back to the prompt and noticed the first sentence was a stubby confirm-beat. "Staff Engineer at Amazon." reads like a form receipt before the warmth arrives.
The fix. The shape was rewritten to fuse the field name into the interpretation: "Senior PM at Meta tells me you can run at serious platform scale. Director feels like a clean next chapter." My original line was moved to the Bad column of the prompt, with the note "(stubby confirm-beat; should be fused into one sentence)."
What it taught me. Evals catch rule violations and tool-call failures. They don't catch stubby prose. The production layer (the way the work feels in a real conversation) is the layer evals can't replace.
I also left a bigger restructure on the runway. A doc proposing every phase do exactly one job (not how engineering originally set it up). Backed by the prompts already behaving that way under CHECK FIRST.
It needed backend changes I couldn't fit in a one-week ticket, so I wrote it up and left it to pick up sometime after beta. And the work isn't done. I’m still fighting for it.
Not because there are more phases to ship. Because the case for letting an LLM drive a high-stakes flow isn't settled inside the company. Some folks would rather onboarding be deterministic. An LLM doesn't work that way. Every time the model surprises you, the conversation reopens I my opinion.
Here's what that conversation looks like in motion for now.